Free Preparation Discussions
Free Microsoft DP-100 Exam Dumps - Page 6
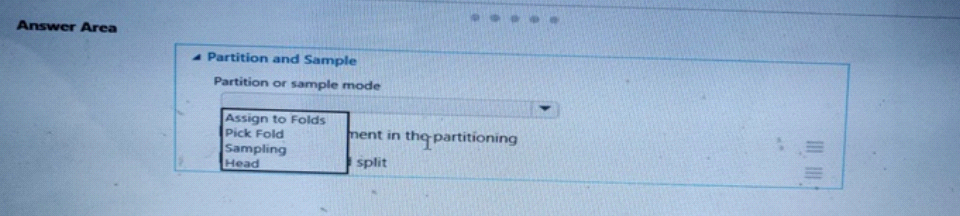
Hotspot
You have a dataset contains 2,000 rows. You arc building a machine learning classification model by using Azure Machine Learning Studio. You add a Partition and Sample module to the experiment.
You need to configure the module. You must meet the following requirements:
* Divide the data into subsets.
* Assign the rows into folds using a round-robin method.
* Allow rows in the dataset to be reused.
How should you configure the module? To answer select the appropriate Options m the dialog box in the answer area.
NOTE: Each correct selection is worth one point.

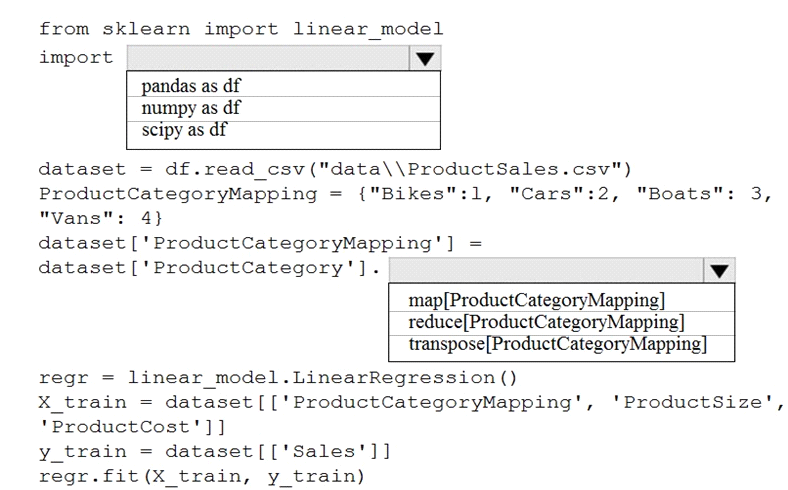
Hotspot
You are creating a machine learning model in Python. The provided dataset contains several numerical columns and one text column. The text column represents a product's category. The product category will always be one of the following:
*Bikes
*Cars
*Vans
*Boats
You are building a regression model using the scikit-learn Python package.
You need to transform the text data to be compatible with the scikit-learn Python package.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
DragDrop
You configure a Deep Learning Virtual Machine for Windows.
You need to recommend tools and frameworks to perform the following:
*Build deep neural network (DNN) models
*Perform interactive data exploration and visualization
Which tools and frameworks should you recommend? To answer, drag the appropriate tools to the correct tasks. Each tool may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.





Hotspot
You are using the Azure Machine Learning Service to automate hyperparameter exploration of your neural network classification model.
You must define the hyperparameter space to automatically tune hyperparameters using random sampling according to following requirements:
*The learning rate must be selected from a normal distribution with a mean value of 10 and a standard deviation of 3.
*Batch size must be 16, 32 and 64.
*Keep probability must be a value selected from a uniform distribution between the range of 0.05 and 0.1.
You need to use the param_sampling method of the Python API for the Azure Machine Learning Service.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

MultipleChoice
Your team is building a data engineering and data science development environment.
The environment must support the following requirements:
*support Python and Scala
*compose data storage, movement, and processing services into automated data pipelines
*the same tool should be used for the orchestration of both data engineering and data science
*support workload isolation and interactive workloads
*enable scaling across a cluster of machines
You need to create the environment.
What should you do?
OptionsDragDrop
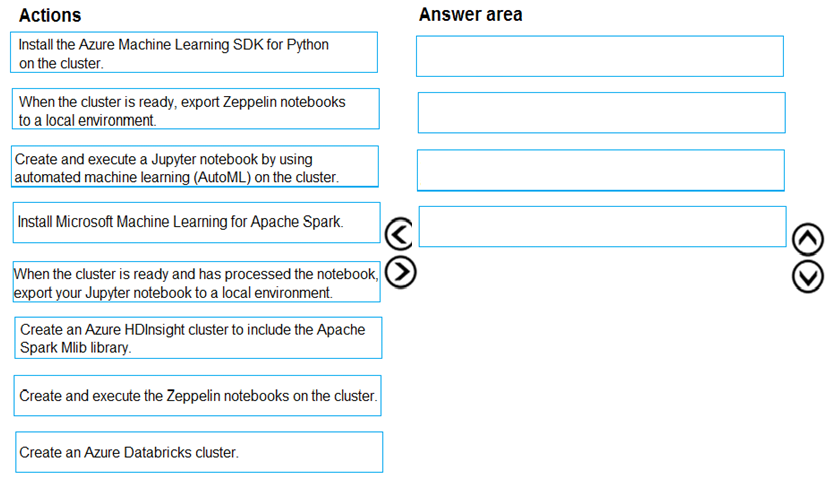
You are building an intelligent solution using machine learning models.
The environment must support the following requirements:
*Data scientists must build notebooks in a cloud environment
*Data scientists must use automatic feature engineering and model building in machine learning pipelines.
*Notebooks must be deployed to retrain using Spark instances with dynamic worker allocation.
*Notebooks must be exportable to be version controlled locally.
You need to create the environment.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.








MultipleChoice
You plan to build a team data science environment. Data for training models in machine learning pipelines will
be over 20 GB in size.
You have the following requirements:
*Models must be built using Caffe2 or Chainer frameworks.
*Data scientists must be able to use a data science environment to build the machine learning pipelines and train models on their personal devices in both connected and disconnected network environments.
*Personal devices must support updating machine learning pipelines when connected to a network.
You need to select a data science environment.
Which environment should you use?
OptionsMultipleChoice
You are developing deep learning models to analyze semi-structured, unstructured, and structured data types.
You have the following data available for model building:
*Video recordings of sporting events
*Transcripts of radio commentary about events
*Logs from related social media feeds captured during sporting events
You need to select an environment for creating the model.
Which environment should you use?
OptionsHotspot
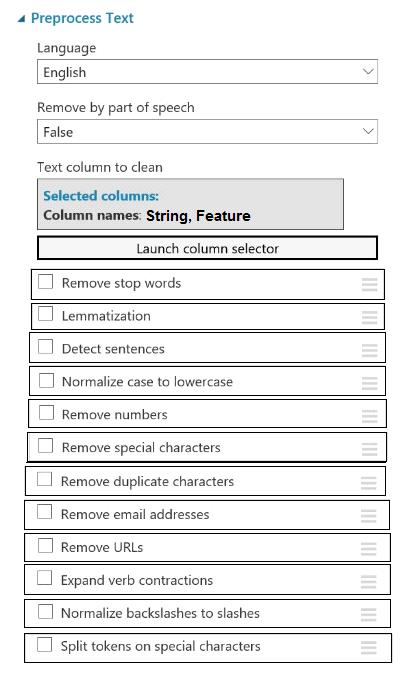
You plan to preprocess text from CSV files. You load the Azure Machine Learning Studio default stop words list.
You need to configure the Preprocess Text module to meet the following requirements:
*Ensure that multiple related words from a single canonical form.
*Remove pipe characters from text.
*Remove words to optimize information retrieval.
Which three options should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
MultipleChoice
You create a binary classification model by using Azure Machine Learning Studio.
You must tune hyperparameters by performing a parameter sweep of the model. The parameter sweep must meet the following requirements:
*iterate all possible combinations of hyperparameters
*minimize computing resources required to perform the sweep
*You need to perform a parameter sweep of the model.
Which parameter sweep mode should you use?
Options
