Free Preparation Discussions
Free Microsoft DP-100 Exam Dumps July 2026
Here you can find all the free questions related with Microsoft Designing and Implementing a Data Science Solution on Azure (DP-100) exam. You can also find on this page links to recently updated premium files with which you can practice for actual Microsoft Designing and Implementing a Data Science Solution on Azure Exam. These premium versions are provided as DP-100 exam practice tests, both as desktop software and browser based application, you can use whatever suits your style. Feel free to try the Designing and Implementing a Data Science Solution on Azure Exam premium files for free, Good luck with your Microsoft Designing and Implementing a Data Science Solution on Azure Exam.MultipleChoice
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create an Azure Machine Learning service datastore in a workspace. The datastore contains the following files:
* /data/2018/Q1 .csv
* /data/2018/Q2.csv
* /data/2018/Q3.csv
* /data/2018/Q4.csv
* /data/2019/Q1.csv
All files store data in the following format:
id,M,f2,l
1,1,2,0
2,1,1,1
32,10
You run the following code:
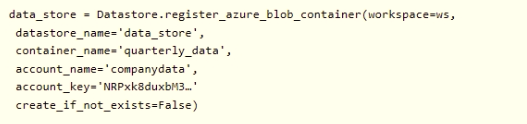
You need to create a dataset named training_data and load the data from all files into a single data frame by using the following code:

Solution: Run the following code:

Does the solution meet the goal?
OptionsOrderList
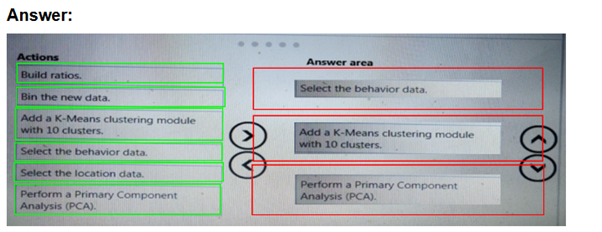
You need to modify the inputs for the global penalty event model to address the bias and variance issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
MultipleChoice
You manage an Azure Al Foundry project. You plan to create a vector index for a RAG solution. You need to build the index remotely by using a script.
Which two data sources can you use? Each correct answer presents a complete solution. Choose two. NOTE: Each correct selection is worth one point.
OptionsMultipleChoice
You manage an Azure Al Foundry project.
You plan to develop a RAG solution from a set of PDF files. To achieve this, you plan to create a vector index from the dat
a. You need to select the location of the data you plan to index.
Which two data sources can you use? Each correct answer presents a complete solution. Choose two. NOTE: Each correct selection is worth one point.
OptionsHotspot
You are using hyperparameter tuning in Azure Machine Learning Python SDK v2 to train a model. You configure the hyperparameter tuning experiment by running the following code:

For each of the following statements select Yes if the statement is true. Otherwise, select No. NOTE: Fach correct selection is worth one paint.

MultipleChoice
You manage an Azure Machine Learning workspace named workspaces
You must develop Python SDK v2 code to attach an Azure Synapse Spark pool as a compute target in workspaces The code must invoke the constructor of the SynapseSparkCompute class.
You need to invoke the constructor.
What should you use?
OptionsHotspot
You create an Azure Machine Learning dataset containing automobile price dat
a. The dataset includes 10.000 rows and 10 columns. You use the Azure Machine Learning designer to transform the dataset by using an Execute Python Script component and custom code.
The code must combine three columns to create a new column.
You need to configure the code function.
Which configurations should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Hotspot
A biomedical research company plans to enroll people in an experimental medical treatment trial.
You create and train a binary classification model to support selection and admission of patients to the trial. The model includes the following features: Age, Gender, and Ethnicity.
The model returns different performance metrics for people from different ethnic groups.
You need to use Fairlearn to mitigate and minimize disparities for each category in the Ethnicity feature.
Which technique and constraint should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Hotspot
You are using a decision tree algorithm. You have trained a model that generalizes well at a tree depth equal to 10.
You need to select the bias and variance properties of the model with varying tree depth values.
Which properties should you select for each tree depth? To answer, select the appropriate options in the answer area.

Hotspot
You are performing a classification task in Azure Machine Learning Studio.
You must prepare balanced testing and training samples based on a provided data set.
You need to split the data with a 0.75:0.25 ratio.
Which value should you use for each parameter? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.