Free Preparation Discussions
Free Databricks Certified Data Engineer Professional Exam Dumps
Here you can find all the free questions related with Databricks Certified Data Engineer Professional (Databricks Certified Data Engineer Professional) exam. You can also find on this page links to recently updated premium files with which you can practice for actual Databricks Certified Data Engineer Professional Exam. These premium versions are provided as Databricks Certified Data Engineer Professional exam practice tests, both as desktop software and browser based application, you can use whatever suits your style. Feel free to try the Databricks Certified Data Engineer Professional Exam premium files for free, Good luck with your Databricks Certified Data Engineer Professional Exam.MultipleChoice
A distributed team of data analysts share computing resources on an interactive cluster with autoscaling configured. In order to better manage costs and query throughput, the workspace administrator is hoping to evaluate whether cluster upscaling is caused by many concurrent users or resource-intensive queries.
In which location can one review the timeline for cluster resizing events?
OptionsMultipleChoice
A nightly job ingests data into a Delta Lake table using the following code:
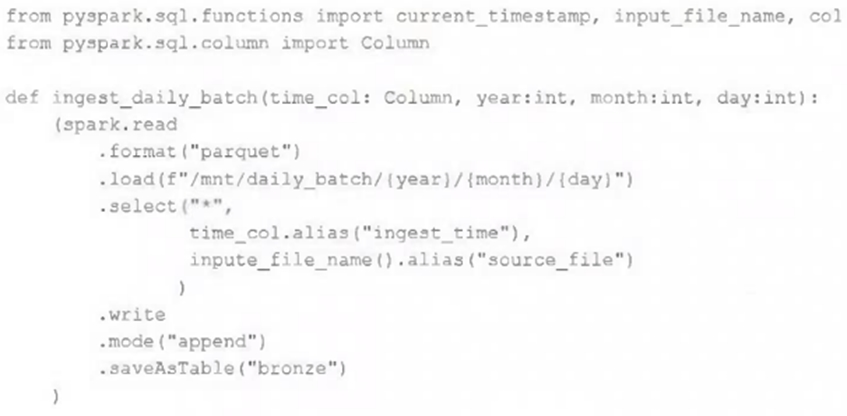
The next step in the pipeline requires a function that returns an object that can be used to manipulate new records that have not yet been processed to the next table in the pipeline.
Which code snippet completes this function definition?
def new_records():
A . return spark.readStream.table('bronze')
B . return spark.readStream.load('bronze')
C .

D .
return spark.read.option('readChangeFeed', 'true').table ('bronze')
E .

MultipleChoice
A nightly job ingests data into a Delta Lake table using the following code:

The next step in the pipeline requires a function that returns an object that can be used to manipulate new records that have not yet been processed to the next table in the pipeline.
Which code snippet completes this function definition?
A) def new_records():
B) return spark.readStream.table('bronze')
C) return spark.readStream.load('bronze')
D) return spark.read.option('readChangeFeed', 'true').table ('bronze')
E)

MultipleChoice
A Delta Lake table representing metadata about content from user has the following schema:
Based on the above schema, which column is a good candidate for partitioning the Delta Table?
Options
