Deal of The Day! Hurry Up, Grab the Special Discount - Save 25% - Ends In 00:00:00 Coupon code: SAVE25
Free Preparation Discussions
Microsoft DP-600 Exam - Topic 1 Question 8 Discussion
Actual exam question for
Microsoft's
DP-600 exam
Question #: 8
Topic #: 1
[All DP-600 Questions]
Topic #: 1
You are analyzing customer purchases in a Fabric notebook by using PySpanc You have the following DataFrames:

You need to join the DataFrames on the customer_id column. The solution must minimize data shuffling. You write the following code.

Which code should you run to populate the results DataFrame?
A)

B)

C)

D)
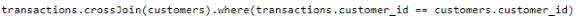
Suggested Answer:
A
Deangelo
8 months agoErick
8 months agoCarlota
8 months agoNorah
8 months agoKathrine
9 months agoCorrie
9 months agoVilma
9 months agoSantos
9 months agoLashawn
9 months agoCandida
9 months agoDorian
9 months agoArlyne
9 months agoEmerson
10 months agoEdmond
10 months agoCeola
10 months agoLoren
10 months agoBeatriz
2 years agoShasta
2 years agoSharita
2 years agoBeatriz
2 years agoSharita
2 years agoBeatriz
2 years agoLouann
2 years agoJean
2 years agoPeter
2 years agoRodolfo
2 years agoCorinne
2 years agoXuan
2 years agoSon
2 years agoLettie
2 years agoAlise
2 years agoPeter
2 years ago