Free Preparation Discussions
HPE7-J02 Exam Questions
- HPE Master ASE Certifications
- HP Storage Integrator Solutions Certifications
- Topic 1: Storage Transport in Multi-Site Solutions: This section evaluates the skills of Storage Architects in describing and applying transport technologies within multi-site solutions. It involves distinguishing between SAN topologies, analyzing transport components, and recommending advanced data protection methods to ensure reliability across enterprise environments.
- Topic 2: HPE Storage Portfolio and Strategy: This domain measures the knowledge of Solution Advisors in positioning HPE’s Storage portfolio within enterprise infrastructure. Candidates must understand HPE Storage hardware, procurement options, available tools, and the overarching storage strategy, including its relevance to enterprise-scale solutions.
- Topic 3: Competitive Positioning of HPE Storage: This part of the exam focuses on the ability of Trusted Advisors to identify competitive opportunities for HPE Storage solutions. It requires articulating HPE’s strengths in comparison to multi-vendor environments, customer needs, and market trends, helping customers make informed technology choices.
- Topic 4: Planning and Validating Storage Solutions: This section assesses the role of Storage Consultants in evaluating complex, multi-vendor environments. Candidates will demonstrate their ability to plan, size, and validate storage solutions tailored for enterprise workloads, ensuring proposals meet customer requirements effectively.
- Topic 5: Remote Support Configuration: This small but important section tests the ability of System Administrators to configure HPE solutions for remote support, ensuring proactive monitoring and timely resolution of technical issues.
- Topic 6: Optimizing the Customer’s Environment: This domain evaluates the skills of Optimization Specialists in identifying opportunities for improvement. Candidates will design and validate optimization plans that enhance customer environments, ensuring measurable performance and efficiency gains.
- Topic 7: Advanced Troubleshooting and Prevention: This section focuses on the ability of Support Engineers to identify root causes of issues and implement advanced preventive measures. It emphasizes building resilience in customer environments to minimize future disruptions.
- Topic 8: Storage Access and Data Protection: This part of the exam tests the expertise of Infrastructure Engineers in configuring storage access, provisioning capacity, and applying replication policies. It also covers disaster recovery validation and role-based access control to secure storage operations.
- Topic 9: Monitoring and Telemetry: This section examines the skills of Cloud Operations Specialists in using HPE or third-party management tools to monitor customer telemetry. Candidates must configure alerts, analyze logs, and evaluate reports to identify SLA trends, outages, and performance issues.
Free HP HPE7-J02 Exam Actual Questions
Note: Premium Questions for HPE7-J02 were last updated On Jul. 11, 2026 (see below)
The storage solution based on the exhibit is deployed at a customer site.
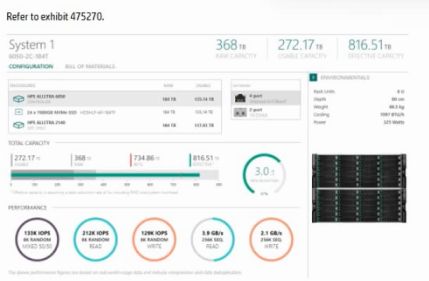
How can the sequential read performance values be enhanced for this configuration?
Detailed Explanatio n:
Rationale for Correct Answe r:
The exhibit shows a system delivering ~2.3 GB/s sequential read. For large-block sequential workloads, aggregate host link bandwidth (number speed of front-end ports) is the primary limiter. Increasing the count of 10/25 Gb iSCSI NICs adds parallel lanes, raising sustained read GB/s to the hosts. This is a recommended first step in HPE sizing before changing protocols.
Analysis of Incorrect Options (Distractors):
A: Adding an expansion shelf increases capacity, not front-end bandwidth.
C: Moving to 32 Gb FC can help, but simply adding more existing 10/25 Gb ports achieves the same goal without a protocol/adapter change and is the straightforward, supported scale-out path.
D: SCM (Storage Class Memory) targets latency/IOPS; it doesn't materially lift sequential GB/s if the link budget is the bottleneck.
Key Concept: Scale front-end connectivity to increase sequential throughput; capacity or media class changes won't fix a link-limited system.
Refer to the exhibit.

A junior engineer is expanding a StoreOnce deployment for a law firm with a hybrid environment. The customer already has Veeam backing up to StoreOnce 3660 Gen 4 at both primary and secondary sites. They want to add Cloud Bank Storage (CBS) to archive into AWS Glacier tier for compliance. The junior engineer has added Cloud Bank licenses for the 80TB onsite capacity at the primary office.
Question : What does the junior engineer need to add to enable this scenario?
The storage solution based on the exhibit is deployed at a customer site.
How can the sequential read performance values be enhanced for this configuration?
Detailed Explanatio n:
Rationale for Correct Answe r:
The exhibit shows a system delivering ~2.3 GB/s sequential read. For large-block sequential workloads, aggregate host link bandwidth (number speed of front-end ports) is the primary limiter. Increasing the count of 10/25 Gb iSCSI NICs adds parallel lanes, raising sustained read GB/s to the hosts. This is a recommended first step in HPE sizing before changing protocols.
Analysis of Incorrect Options (Distractors):
A: Adding an expansion shelf increases capacity, not front-end bandwidth.
C: Moving to 32 Gb FC can help, but simply adding more existing 10/25 Gb ports achieves the same goal without a protocol/adapter change and is the straightforward, supported scale-out path.
D: SCM (Storage Class Memory) targets latency/IOPS; it doesn't materially lift sequential GB/s if the link budget is the bottleneck.
Key Concept: Scale front-end connectivity to increase sequential throughput; capacity or media class changes won't fix a link-limited system.
A customer experienced a replication network outage during setup of Alletra 6000 arrays. They want to allow HPE support remote root access to troubleshoot once the outage is resolved.
How can this be enabled?
The storage solution based on the exhibit is deployed at a customer site.
How can the sequential read performance values be enhanced for this configuration?
Detailed Explanatio n:
Rationale for Correct Answe r:
The exhibit shows a system delivering ~2.3 GB/s sequential read. For large-block sequential workloads, aggregate host link bandwidth (number speed of front-end ports) is the primary limiter. Increasing the count of 10/25 Gb iSCSI NICs adds parallel lanes, raising sustained read GB/s to the hosts. This is a recommended first step in HPE sizing before changing protocols.
Analysis of Incorrect Options (Distractors):
A: Adding an expansion shelf increases capacity, not front-end bandwidth.
C: Moving to 32 Gb FC can help, but simply adding more existing 10/25 Gb ports achieves the same goal without a protocol/adapter change and is the straightforward, supported scale-out path.
D: SCM (Storage Class Memory) targets latency/IOPS; it doesn't materially lift sequential GB/s if the link budget is the bottleneck.
Key Concept: Scale front-end connectivity to increase sequential throughput; capacity or media class changes won't fix a link-limited system.
- Select Question Types you want
- Set your Desired Pass Percentage
- Allocate Time (Hours : Minutes)
- Create Multiple Practice tests with Limited Questions
- Customer Support
Daniel Scott
9 days agoAngela Davis
28 days agoCynthia Martinez
1 month agoAngela Collins
2 months agoRachel Lewis
2 months agoJoseph Peterson
3 months agoFrank Flores
2 months agoMatthew Rivera
2 months agoRebecca Gonzalez
3 months agoJoseph Campbell
2 months agoChristopher Allen
2 months agoNina
3 months agoDortha
4 months agoGiuseppe
4 months agoShanda
4 months agoGolda
4 months agoEladia
5 months agoBenton
5 months agoRodolfo
5 months agoEzekiel
5 months agoAdelle
6 months agoCortney
6 months agoChristiane
6 months agoEzekiel
6 months agoErick
7 months agoChristiane
7 months agoBrent
7 months agoHaydee
7 months agoKara
8 months agoCarmen
8 months agoRaylene
8 months agoLinwood
8 months agoZona
9 months agoAdaline
9 months agoChuck
9 months agoSylvia
9 months agoGilberto
9 months agoFletcher
10 months agoMarget
10 months agoRosalia
10 months agoLynda
10 months agoIsadora
10 months agoLashaun
10 months ago