Free Preparation Discussions
Microsoft DP-100 Exam Questions
Free Microsoft DP-100 Exam Actual Questions
Note: Premium Questions for DP-100 were last updated On 08-06-2026 (see below)
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create a model to forecast weather conditions based on historical data.
You need to create a pipeline that runs a processing script to load data from a datastore and pass the processed data to a machine learning model training script.
Solution: Run the following code:
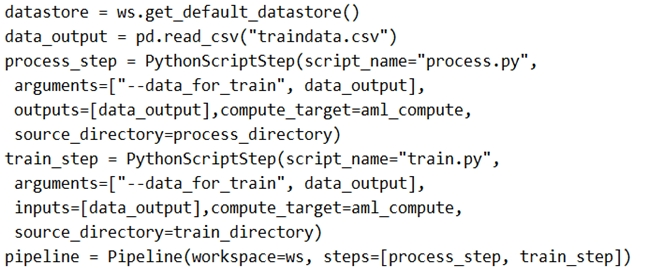
Does the solution meet the goal?
The two steps are present: process_step and train_step
Note:
Data used in pipeline can be produced by one step and consumed in another step by providing a PipelineData object as an output of one step and an input of one or more subsequent steps.
PipelineData objects are also used when constructing Pipelines to describe step dependencies. To specify that a step requires the output of another step as input, use a PipelineData object in the constructor of both steps.
For example, the pipeline train step depends on the process_step_output output of the pipeline process step:
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.pipeline.steps import PythonScriptStep
datastore = ws.get_default_datastore()
process_step_output = PipelineData('processed_data', datastore=datastore)
process_step = PythonScriptStep(script_name='process.py',
arguments=['--data_for_train', process_step_output],
outputs=[process_step_output],
compute_target=aml_compute,
source_directory=process_directory)
train_step = PythonScriptStep(script_name='train.py',
arguments=['--data_for_train', process_step_output],
inputs=[process_step_output],
compute_target=aml_compute,
source_directory=train_directory)
pipeline = Pipeline(workspace=ws, steps=[process_step, train_step])
https://docs.microsoft.com/en-us/python/api/azureml-pipeline-core/azureml.pipeline.core.pipelinedata?view=azure-ml-py
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are creating a new experiment in Azure Machine Learning Studio.
One class has a much smaller number of observations than the other classes in the training set.
You need to select an appropriate data sampling strategy to compensate for the class imbalance.
Solution: You use the Scale and Reduce sampling mode.
Does the solution meet the goal?
Instead use the Synthetic Minority Oversampling Technique (SMOTE) sampling mode.
Note: SMOTE is used to increase the number of underepresented cases in a dataset used for machine learning. SMOTE is a better way of increasing the number of rare cases than simply duplicating existing cases.
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote
You train a machine learning model.
You must deploy the model as a real-time inference service for testing. The service requires low CPU utilization and less than 48 MB of RAM. The compute target for the deployed service must initialize automatically while minimizing cost and administrative overhead.
Which compute target should you use?
Azure Container Instances (ACI) are suitable only for small models less than 1 GB in size.
Use it for low-scale CPU-based workloads that require less than 48 GB of RAM.
Note: Microsoft recommends using single-node Azure Kubernetes Service (AKS) clusters for dev-test of larger models.
https://docs.microsoft.com/id-id/azure/machine-learning/how-to-deploy-and-where
You manage an Azure Machine Learning workspace by using the Azure CLI ml extension v2. You need to define a YAML schema to create a compute cluster. Which schema should you use?
You are using Azure Machine Learning to monitor a trained and deployed model. You implement Event Grid to respond to Azure Machine Learning events.
Model performance has degraded due to model input data changes.
You need to trigger a remediation ML pipeline based on an Azure Machine Learning event.
Which event should you use?
- Select Question Types you want
- Set your Desired Pass Percentage
- Allocate Time (Hours : Minutes)
- Create Multiple Practice tests with Limited Questions
- Customer Support
Jeffrey Anderson
5 days agoSteven Edwards
27 days agoLinda Howard
1 month agoSusan Flores
2 months agoKenneth Nelson
1 month agoWilliam Lopez
2 months agoKaren Bell
1 month agoBrenda Murphy
1 month agoJoshua Thompson
28 days agoGarry
2 months agoCatina
3 months agoEsteban
3 months agoTiera
3 months agoYuette
3 months agoFlo
4 months agoMargurite
4 months agoDonette
4 months agoTaryn
4 months agoDiane
5 months agoTomas
5 months agoJesus
5 months agoTyra
5 months agoLea
6 months agoKimberlie
6 months agoMelina
6 months agoAja
7 months agoJacquline
7 months agoHildegarde
7 months agoHalina
7 months agoTori
8 months agoRebeca
8 months agoMitsue
8 months agoRose
8 months agoEileen
9 months agoLaquita
9 months agoJenifer
9 months agoHoa
9 months agoMila
12 months agoCherry
1 year agoTiffiny
1 year agoChantay
1 year agoLeonora
1 year agoCandida
1 year agoAnnelle
1 year agoProvidencia
2 years agoTess
2 years agoYolando
2 years agoLina
2 years agoKristeen
2 years agoZachary
2 years agoChun
2 years agoCarin
2 years agoVesta
2 years agoLelia
2 years agoAlonzo
2 years agoViva
2 years agoStefan
2 years agoViva
2 years agoCordelia
2 years agoCatherin
2 years agoSilva
2 years agoJacquline
2 years agoLorenza
2 years agoMargo
2 years agoJeanice
2 years agoMarlon
2 years agoKati
2 years agoGarii
2 years agotokyo
2 years agoMark james
2 years agoAlizabith
2 years ago