Free Preparation Discussions
IBM C2090-011 Exam Questions
- Topic 1: Data Transformations Categorical variables, Computing variables/ Counting values across variables/ Counting values across cases, Recoding, Variables
- Topic 2: Operations/Running IBM SPSS Statistics General use, Operations, Settings, Syntax, Variables
- Topic 3: Basic Inferential Statistics Correlations, Chi-square, Regression, Statistics::Error, T-Test, Statistics
- Topic 4: Reading and Defining Data Datasets, Reading data, Variables
- Topic 5: Output: Editing and Exploring Charts, Exporting results, Pivot Tables Editor, ScaleData::Boxplots, ScaleVariable charts, Scatterplots, TableLooks
- Topic 6: Data Management Adding cases, Aggregation,Duplicate cases, SelectCases, SplitFile
- Topic 7: Data Understanding/Descriptives Crosstabs, Descriptive statistics, Dispersion, Procedure, Frequencies, Means procedure, Statistics
Free IBM C2090-011 Exam Actual Questions
Note: Premium Questions for C2090-011 were last updated On 29-05-2024 (see below)
In the Aggregate data procedure1 if you specify more than one Break Variable, ________ in the Break Variables list will determine case order.
The IBM SPSS Statistics Select Cases provides various ways to select cases included in further analysis. If you needed to conduct analysis on those respondents whose age is more than 30 years, earning in excess of $40000, which option in this dialog would you choose to specify these criteria?
As the sample size increases, the amount of variabilit9 in the distribution of sample means increases.
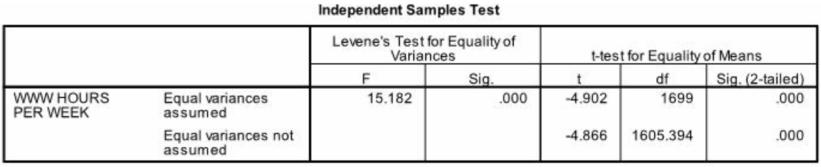
Which interpretation is correct for the Independent Samples T-Test table shown below?
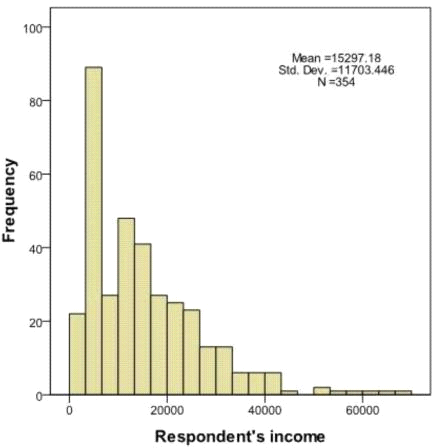
You have been asked to create a categorical variable from a scale variable, income, illustrated in the histogram below. The resulting categorical variable must have 5 categories with an approximately equal number of cases in each category. Which way would you accomplish this using the IBM SPSS Statistics Visual Binning dialog?
- Select Question Types you want
- Set your Desired Pass Percentage
- Allocate Time (Hours : Minutes)
- Create Multiple Practice tests with Limited Questions
- Customer Support
Currently there are no comments in this discussion, be the first to comment!