Free Preparation Discussions
Google Professional Machine Learning Engineer Exam Questions
- Google Cloud Certified Certifications
- Google Cloud Engineer Certifications
Free Google Professional Machine Learning Engineer Exam Actual Questions
Note: Premium Questions for Professional Machine Learning Engineer were last updated On Jun. 19, 2026 (see below)
You have recently used TensorFlow to train a classification model on tabular data You have created a Dataflow pipeline that can transform several terabytes of data into training or prediction datasets consisting of TFRecords. You now need to productionize the model, and you want the predictions to be automatically uploaded to a BigQuery table on a weekly schedule. What should you do?
Vertex AI is a service that allows you to create and train ML models using Google Cloud technologies. You can use Vertex AI to import the model that you trained with TensorFlow and store it in the Vertex AI Model Registry. The Vertex AI Model Registry is a service that allows you to store and manage your ML models on Google Cloud. You can then use Vertex AI Pipelines to create a pipeline that uses the DataflowPythonJobOp and the ModelBatchPredictOp components. The DataflowPythonJobOp component is a component that allows you to run a Dataflow job using a Python script. Dataflow is a service that allows you to create and run scalable and portable data processing pipelines on Google Cloud. You can use the DataflowPythonJobOp component to reuse the data processing logic that you created for transforming the data into TFRecords. The ModelBatchPredictOp component is a component that allows you to run a batch prediction job using a model from the Vertex AI Model Registry. Batch prediction is a type of prediction that provides high-throughput responses to large batches of input data. You can use the ModelBatchPredictOp component to make predictions using the TFRecords from the DataflowPythonJobOp component and the model from the Vertex AI Model Registry. You can also configure the ModelBatchPredictOp component to automatically upload the predictions to a BigQuery table. BigQuery is a service that allows you to store and query large amounts of data in a scalable and cost-effective way. You can use BigQuery to store and analyze the predictions from your model. You can also schedule the pipeline to run on a weekly basis, so that the predictions are updated regularly. By using Vertex AI, Vertex AI Pipelines, Dataflow, and BigQuery, you can productionize the model and upload the predictions to a BigQuery table on a weekly schedule.Reference:
Vertex AI documentation
Vertex AI Pipelines documentation
Dataflow documentation
BigQuery documentation
Preparing for Google Cloud Certification: Machine Learning Engineer Professional Certificate
You need to build classification workflows over several structured datasets currently stored in BigQuery. Because you will be performing the classification several times, you want to complete the following steps without writing code: exploratory data analysis, feature selection, model building, training, and hyperparameter tuning and serving. What should you do?
AutoML Tables is a service that allows you to automatically build and deploy state-of-the-art machine learning models on structured data without writing code. You can use AutoML Tables to perform the following steps for the classification task:
Exploratory data analysis: AutoML Tables provides a graphical user interface (GUI) and a command-line interface (CLI) to explore your data, visualize statistics, and identify potential issues.
Feature selection: AutoML Tables automatically selects the most relevant features for your model based on the data schema and the target column. You can also manually exclude or include features, or create new features from existing ones using feature engineering.
Model building: AutoML Tables automatically builds and evaluates multiple machine learning models using different algorithms and architectures. You can also specify the optimization objective, the budget, and the evaluation metric for your model.
Training and hyperparameter tuning: AutoML Tables automatically trains and tunes your model using the best practices and techniques from Google's research and engineering teams. You can monitor the training progress and the performance of your model on the GUI or the CLI.
Serving: AutoML Tables automatically deploys your model to a fully managed, scalable, and secure environment. You can use the GUI or the CLI to request predictions from your model, either online (synchronously) or offline (asynchronously).
[AutoML Tables documentation]
[AutoML Tables overview]
[AutoML Tables how-to guides]
While performing exploratory data analysis on a dataset, you find that an important categorical feature has 5% null values. You want to minimize the bias that could result from the missing values. How should you handle the missing values?
The best option for handling missing values in a categorical feature is to replace them with a placeholder category indicating a missing value. This is a type of imputation, which is a method of estimating the missing values based on the observed data. Imputing the missing values with a placeholder category preserves the information that the data is missing, and avoids introducing bias or distortion in the feature distribution. It also allows the machine learning model to learn from the missingness pattern, and potentially use it as a predictor for the target variable. The other options are not suitable for handling missing values in a categorical feature, because:
Removing the rows with missing values and upsampling the dataset by 5% would reduce the size of the dataset and potentially lose important information. It would also introduce sampling bias and overfitting, as the upsampling process would create duplicate or synthetic observations that do not reflect the true population.
Replacing the missing values with the feature's mean would not make sense for a categorical feature, as the mean is a numerical measure that does not capture the mode or frequency of the categories. It would also create a new category that does not exist in the original data, and might confuse the machine learning model.
Moving the rows with missing values to the validation dataset would compromise the validity and reliability of the model evaluation, as the validation dataset would not be representative of the test or production data. It would also reduce the amount of data available for training the model, and might introduce leakage or inconsistency between the training and validation datasets.Reference:
Imputation of missing values
Effective Strategies to Handle Missing Values in Data Analysis
How to Handle Missing Values of Categorical Variables?
Google Cloud launches machine learning engineer certification
Google Professional Machine Learning Engineer Certification
Professional ML Engineer Exam Guide
Preparing for Google Cloud Certification: Machine Learning Engineer Professional Certificate
Your team has been tasked with creating an ML solution in Google Cloud to classify support requests for one of your platforms. You analyzed the requirements and decided to use TensorFlow to build the classifier so that you have full control of the model's code, serving, and deployment. You will use Kubeflow pipelines for the ML platform. To save time, you want to build on existing resources and use managed services instead of building a completely new model. How should you build the classifier?
Transfer learning is a technique that leverages the knowledge and weights of a pre-trained model and adapts them to a new task or domain1.Transfer learning can save time and resources by avoiding training a model from scratch, and can also improve the performance and generalization of the model by using a larger and more diverse dataset2.AI Platform provides several established text classification models that can be used for transfer learning, such as BERT, ALBERT, or XLNet3.These models are based on state-of-the-art natural language processing techniques and can handle various text classification tasks, such as sentiment analysis, topic classification, or spam detection4. By using one of these models on AI Platform, you can customize the model's code, serving, and deployment, and use Kubeflow pipelines for the ML platform. Therefore, using an established text classification model on AI Platform to perform transfer learning is the best option for this use case.
Transfer Learning - Machine Learning's Next Frontier
A Comprehensive Hands-on Guide to Transfer Learning with Real-World Applications in Deep Learning
Text classification models
Text Classification with Pre-trained Models in TensorFlow
You are training an object detection model using a Cloud TPU v2. Training time is taking longer than expected. Based on this simplified trace obtained with a Cloud TPU profile, what action should you take to decrease training time in a cost-efficient way?
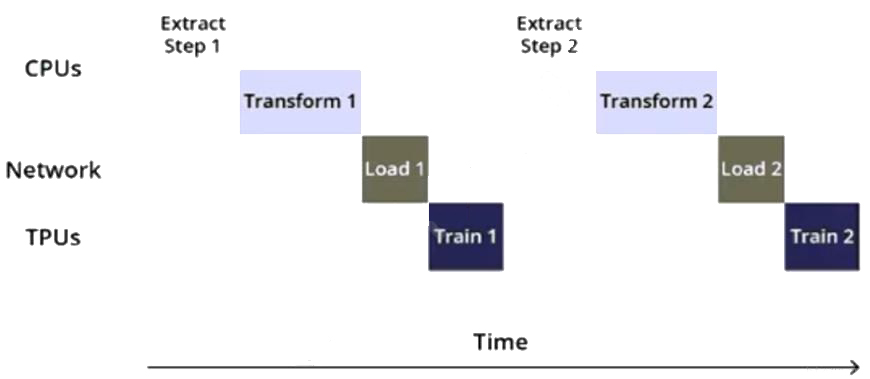
The trace in the question shows that the training time is taking longer than expected. This is likely due to the input function not being optimized. To decrease training time in a cost-efficient way, the best option is to rewrite the input function using parallel reads, parallel processing, and prefetch. This will allow the model to process the data more efficiently and decrease training time.Reference:
[Cloud TPU Performance Guide]
[Data input pipeline performance guide]
- Select Question Types you want
- Set your Desired Pass Percentage
- Allocate Time (Hours : Minutes)
- Create Multiple Practice tests with Limited Questions
- Customer Support
Charles Davis
5 days agoRachel Wright
25 days agoRobert Martinez
1 month agoEmma Edwards
2 months agoJennifer Davis
2 months agoNathan Howard
2 months agoKevin Moore
2 months agoAdam King
2 months agoLinda Jones
2 months agoAdam King
1 month agoIsreal
3 months agoMerissa
3 months agoRene
3 months agoEun
3 months agoJamal
4 months agoSina
4 months agoSena
4 months agoKristeen
4 months agoYoko
5 months agoGlendora
5 months agoTarra
5 months agoErinn
5 months agoJimmie
6 months agoCherilyn
6 months agoGerri
6 months agoMattie
6 months agoEffie
7 months agoBong
7 months agoLacey
7 months agoEladia
7 months agoBette
8 months agoAntonio
8 months agoGail
8 months agoMollie
8 months agoLorenza
9 months agoMaryann
9 months agoTaryn
9 months agoRolande
9 months agoAntonio
9 months agoChu
10 months agoNickie
10 months agoLeonora
10 months agoLemuel
11 months agoLinette
12 months agoTamie
1 year agoNina
1 year agoYoko
1 year agoKenneth
1 year agoDaniel
1 year agoCasie
1 year agoGladys
1 year agoRessie
1 year agoRonnie
1 year agoClemencia
1 year agoMarta
1 year agoPenney
1 year agoTeddy
1 year agoStanford
1 year agoAngelyn
2 years agoJonell
2 years agoNickie
2 years agoNoe
2 years agoBlondell
2 years agoMurray
2 years agoChaya
2 years agoDorathy
2 years agoLenora
2 years agoCarey
2 years agoSage
2 years agoLura
2 years agoTheola
2 years agoSalina
2 years agoTheresia
2 years agoGeorgene
2 years agoBeth
2 years agoMargart
2 years agoThaddeus
2 years agoElfrieda
2 years agoJesse
2 years agoCaprice
2 years agoXochitl
2 years agopetal
2 years ago