Free Preparation Discussions
Google Associate Cloud Engineer Exam Questions
Free Google Associate Cloud Engineer Exam Actual Questions
Note: Premium Questions for Associate Cloud Engineer were last updated On Jun. 10, 2026 (see below)
Your company uses Pub/Sub for event-driven workloads. You have a subscription named email-updates attached to the new-orders topic. You need to fetch and acknowledge waiting messages from this subscription. What should you do?
The goal is to pull (fetch) messages from a subscription and acknowledge them.
The gcloud pubsub subscriptions **pull** command retrieves messages from a specified subscription.
The --auto-ack flag instructs the command to automatically acknowledge the messages after they are successfully retrieved, combining the two required actions into one command.
'Pulls one or more messages from the specified subscription. To acknowledge the pulled messages, use the --auto-ack flag.'
You have an application that uses Cloud Spanner as a backend database. The application has a very predictable traffic pattern. You want to automatically scale up or down the number of Spanner nodes depending on traffic. What should you do?
As to mexblood1's point, CPU utilization is a recommended proxy for traffic when it comes to Cloud Spanner. See: Alerts for high CPU utilization The following table specifies our recommendations for maximum CPU usage for both single-region and multi-region instances. These numbers are to ensure that your instance has enough compute capacity to continue to serve your traffic in the event of the loss of an entire zone (for single-region instances) or an entire region (for multi-region instances). -https://cloud.google.com/spanner/docs/cpu-utilization
You need to configure IAM access audit logging in BigQuery for external auditors. You want to follow Google-recommended practices. What should you do?
https://cloud.google.com/iam/docs/job-functions/auditing#scenario_external_auditors
Because if you directly add users to the IAM roles, then if any users left the organization then you have to remove the users from multiple places and need to revoke his/her access from multiple places. But, if you put a user into a group then its very easy to manage these type of situations. Now, if any user left then you just need to remove the user from the group and all the access got revoked
The organization creates a Google group for these external auditors and adds the current auditor to the group. This group is monitored and is typically granted access to the dashboard application. During normal access, the auditors' Google group is only granted access to view the historic logs stored in BigQuery. If any anomalies are discovered, the group is granted permission to view the actual Cloud Logging Admin Activity logs via the dashboard's elevated access mode. At the end of each audit period, the group's access is then revoked. Data is redacted using Cloud DLP before being made accessible for viewing via the dashboard application. The table below explains IAM logging roles that an Organization Administrator can grant to the service account used by the dashboard, as well as the resource level at which the role is granted.
You deployed a new application inside your Google Kubernetes Engine cluster using the YAML file specified below.
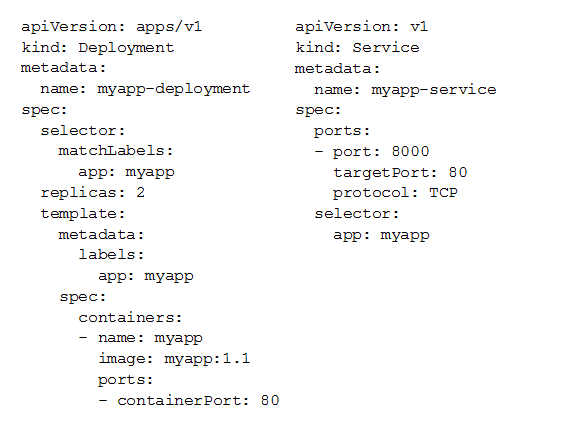
You check the status of the deployed pods and notice that one of them is still in PENDING status:

You want to find out why the pod is stuck in pending status. What should you do?
https://kubernetes.io/docs/tasks/debug-application-cluster/debug-application/#debugging-pods
You have a single binary application that you want to run on Google Cloud Platform. You decided to automatically scale the application based on underlying infrastructure CPU usage. Your organizational policies require you to use virtual machines directly. You need to ensure that the application scaling is operationally efficient and completed as quickly as possible. What should you do?
Managed instance groups offer autoscaling capabilities that let you automatically add or delete instances from a managed instance group based on increases or decreases in load (CPU Utilization in this case). Autoscaling helps your apps gracefully handle increases intraffic and reduce costs when the need for resources is lower. You define the autoscaling policy and the autoscaler performs automatic scaling based on the measured load (CPU Utilization in this case). Autoscaling works by adding more instances to your instance group when there is more load (upscaling), and deleting instances when the need for instances is lowered (downscaling). Ref:https://cloud.google.com/compute/docs/autoscaler
- Select Question Types you want
- Set your Desired Pass Percentage
- Allocate Time (Hours : Minutes)
- Create Multiple Practice tests with Limited Questions
- Customer Support
Mark Anderson
14 days agoJason Moore
17 days agoRonald Rivera
1 month agoKevin Nguyen
25 days agoSharon Nelson
28 days agoHeather Lewis
30 days agoGerald Jones
1 month agoFrank Reed
1 month agoDaniel Gonzalez
2 months agoKristel
2 months agoVerona
3 months agoLynelle
3 months agoShalon
3 months agoWhitley
3 months agoKristeen
4 months agoMeghan
4 months agoAlberto
4 months agoDominga
4 months agoGladys
5 months agoMi
5 months agoTrina
5 months agoJose
5 months agoLavonne
6 months agoStefan
6 months agoHoa
6 months agoKiley
6 months agoAbraham
7 months agoWalker
7 months agoCecily
7 months agoCarlene
7 months agoJohnetta
8 months agoMalinda
8 months agoTalia
8 months agoGianna
8 months agoMuriel
9 months agoAdaline
9 months agoTien
9 months agoMicah
9 months agoMargurite
9 months agoKarima
11 months agoMauricio
12 months agoPeter
1 year agoDevon
1 year agoStaci
1 year agoShelia
1 year agoAvery
1 year agoRoselle
1 year agoLuisa
1 year agoLeonida
1 year agoKati
1 year agoSheldon
1 year agoGerald
1 year agoTwanna
1 year agoTambra
1 year agoRoyal
1 year agoDelmy
1 year agoLorrine
1 year agoLoreta
2 years agoArlyne
2 years agoKristofer
2 years agoKeneth
2 years agoErasmo
2 years agoSkye
2 years agoClaribel
2 years agoGolda
2 years agoBrinda
2 years agoErick
2 years agoYvonne
2 years agoBette
2 years agoTennie
2 years agoBev
2 years agoLashaunda
2 years agoMerlyn
2 years agoJunita
2 years agoMadonna
2 years agoKeneth
2 years agoGregoria
2 years agoMabel
2 years agoBrittni
2 years agoCharlesetta
2 years agowibimosentrau
2 years ago