Deal of The Day! Hurry Up, Grab the Special Discount - Save 25% - Ends In 00:00:00 Coupon code: SAVE25
Free Preparation Discussions
Google Professional Data Engineer Exam - Topic 4 Question 60 Discussion
Actual exam question for
Google's
Professional Data Engineer exam
Question #: 60
Topic #: 4
[All Professional Data Engineer Questions]
Topic #: 4
You are collecting loT sensor data from millions of devices across the world and storing the data in BigQuery. Your access pattern is based on recent data tittered by location_id and device_version with the following query:
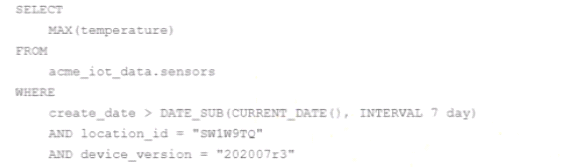
You want to optimize your queries for cost and performance. How should you structure your data?
Suggested Answer:
C
Jolanda
9 months agoSophia
9 months agoSherron
9 months agoAdelaide
9 months agoMickie
9 months agoKate
9 months agoTarra
9 months agoShawana
9 months agoAlexis
10 months agoMurray
10 months agoRozella
10 months ago