Free Preparation Discussions
Databricks Certified Professional Data Scientist Exam - Topic 5 Question 10 Discussion
Topic #: 5
Refer to exhibit
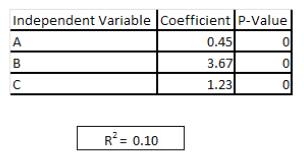
You are asked to write a report on how specific variables impact your client's sales using a data set provided to you by the client. The data includes 15 variables that the client views as directly related to sales, and you are restricted to these variables only. After a preliminary analysis of the data, the following findings were made: 1. Multicollinearity is not an issue among the variables 2. Only three variables-A, B, and C-have significant correlation with sales You build a linear regression model on the dependent variable of sales with the independent variables of A, B, and C. The results of the regression are seen in the exhibit. You cannot request additional dat
a. what is a way that you could try to increase the R2 of the model without artificially inflating it?
Hortencia
5 months agoTheola
6 months agoCurt
6 months agoDan
6 months agoEden
6 months agoAnabel
6 months agoQuinn
6 months agoXochitl
6 months agoBernardine
6 months agoVernice
6 months agoCarmela
6 months agoLeonie
6 months agoBarney
6 months ago